
Meet Zoom AI Companion, your new AI assistant!
Boost productivity and team collaboration with Zoom AI Companion, available at no additional cost with eligible paid Zoom plans.
A new architecture for enterprise AI
Updated on February 13, 2026
Published on February 13, 2026


Xuedong Huang is the Chief Technology Officer (CTO). Prior to Zoom, he was at Microsoft where he served as Azure AI CTO and Technical Fellow. His career is illustrious in the AI space: he began Microsoft’s speech technology group in 1993, led Microsoft’s AI teams to achieve several of the industry’s first human parity milestones in speech recognition, machine translation, natural language understanding, and computer vision, is an IEEE and ACM Fellow and an elected member of the National Academy of Engineering and the American Academy of Arts and Sciences.
Xuedong received his Ph.D. in EE from the University of Edinburgh in 1989 (sponsored by the British ORS and Edinburgh University Scholarship), his MS in CS from Tsinghua University in 1984, and BS in CS from Hunan University in 1982.
Every enterprise wants AI that can follow instructions precisely — yet even the most advanced models often stumble when faced with real-world complexity. For customer service solutions like Zoom Virtual Assistant, where every interaction must comply with internal policies and context, these lapses can erode trust.
The root cause lies in how today’s large language models reason. Their decision-making is implicit, reconstructed from scratch each time they respond. Most corporate knowledge bases are descriptive, not procedural — they tell the AI what to do, not how to do it. As a result, AI agents must infer the right sequence of actions on the fly, leading to inconsistent logic, misapplied constraints, and occasional hallucinations.
At Zoom, we saw this firsthand in our own support operations. To deliver dependable automation, we needed AI that could follow instructions faithfully and learn continuously from its own mistakes.
Traditional methods like prompt tuning or retraining are slow and brittle. They depend on human engineers to spot and fix errors one by one. We wanted something more scalable — a system that could analyze its own reasoning failures, detect recurring flaws, and refine itself automatically.
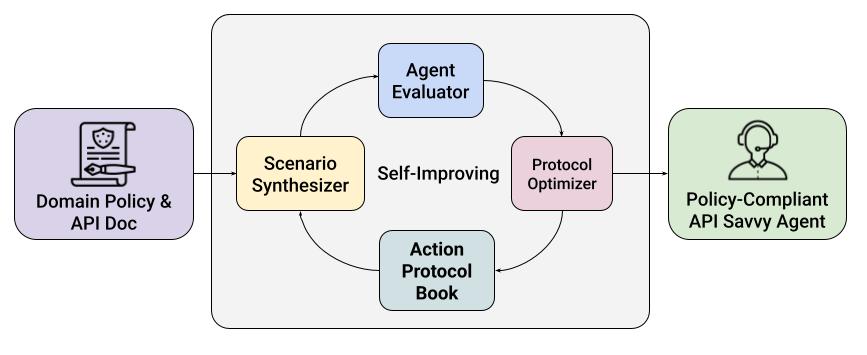
That vision led to the creation of Zoom’s Protocol-Driven Self-Improving Agent framework. Instead of relying on hidden inference chains, we externalized reasoning into a structured, executable format called the Action-Protocol Book (APB).
The APB transforms policy documents into explicit, step-by-step decision protocols. Each action, condition, and fallback is codified — so the agent follows a consistent reasoning order every time. This reduces ambiguity and enforces instruction fidelity across different scenarios.
To make the system self-improving, we built an automated Scenario Synthesizer, Agent Evaluator, and Protocol Optimizer. This approach generates diverse test cases, identifies structural reasoning errors, and updates the APB iteratively.
The result is a closed learning loop: the agent observes its own decision patterns, corrects them, and strengthens its logic — all without manual retraining. Over time, it becomes more robust in its capabilities, more policy-compliant, and more aligned with human expectations.
This approach turns AI from a static model into a self-improving system that can evolve through experience, much like a skilled employee refining judgment through feedback.
In production environments for customer service solutions like Zoom Virtual Agent, the same architecture delivers more reliable, policy‑compliant, and continuously improving customer interactions.
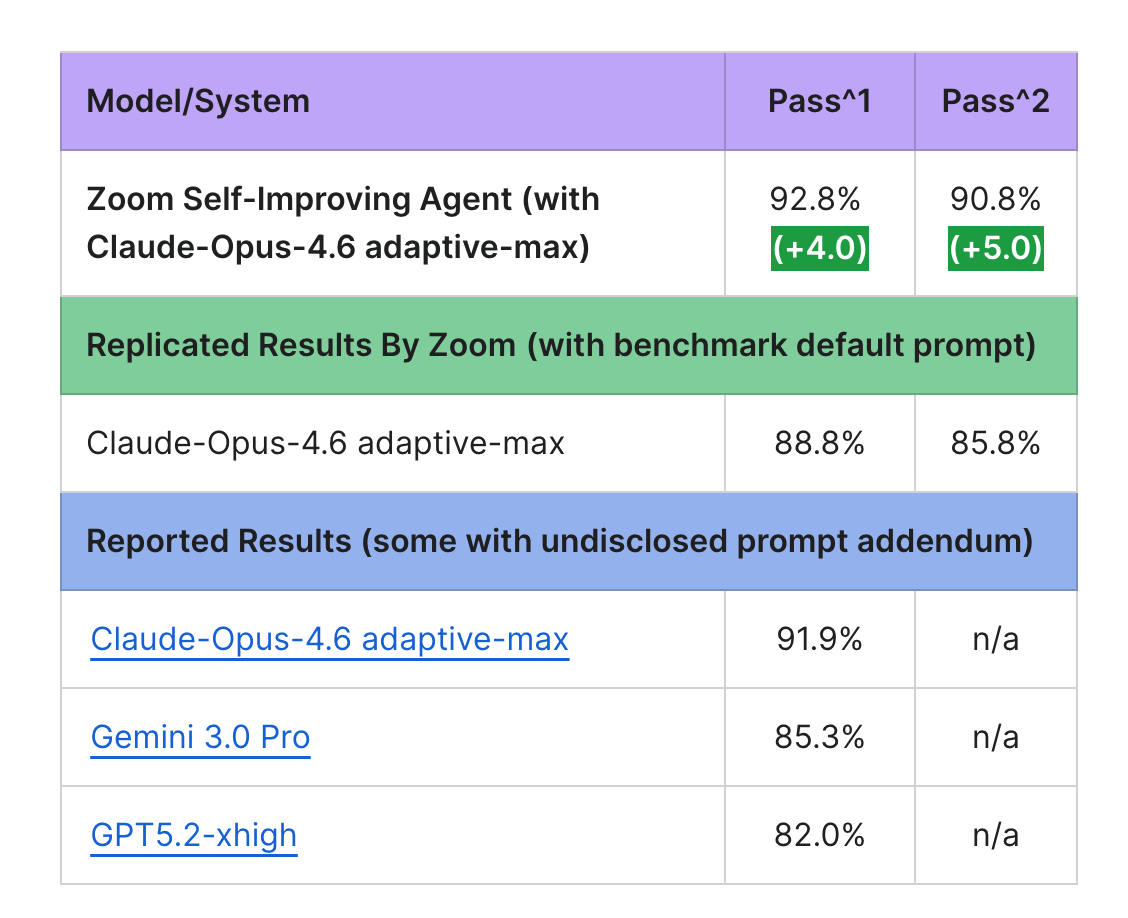
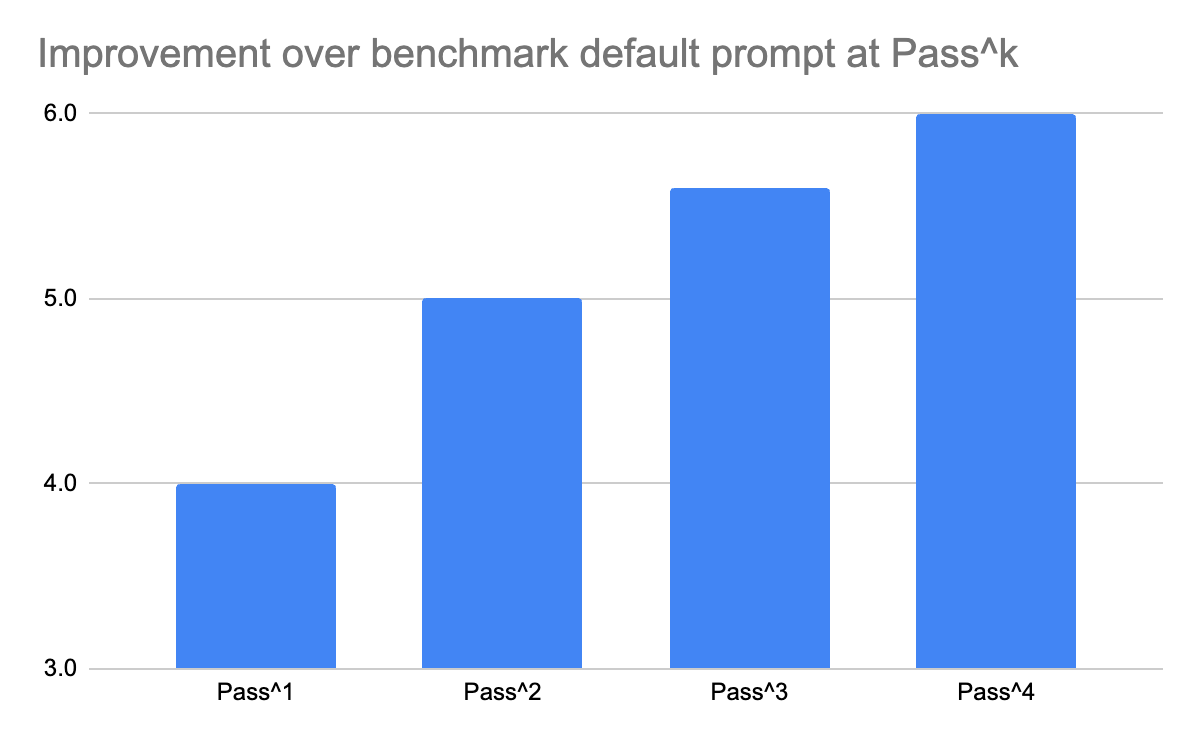
We validated this approach on Tau²Bench – Retail, a benchmark designed to test instruction fidelity and reasoning robustness.
The results were striking:
In production environments for customer service solutions like Zoom Virtual Agent, the same architecture delivers a more reliable, policy‑compliant, and continuously improving customer experience.
Instruction fidelity and continuous learning are the twin pillars of trustworthy AI. Without them, automation that might be impressive in demos remains fragile and unreliable in daily operations.
By combining structured reasoning protocols with automated self‑refinement, Zoom’s approach establishes a new foundation for enterprise AI that is more:
This is more than a benchmark win. It’s a blueprint for how AI can become a dependable digital teammate — one that not only understands instructions but also gets better at following them every day.
Zoom is in the process of applying this framework across our platform — from Zoom Virtual Agent to Zoom AI Companion — so that every interaction reflects the same precision, reliability, and continuous improvement that define our mission to make work more human and intelligent.







