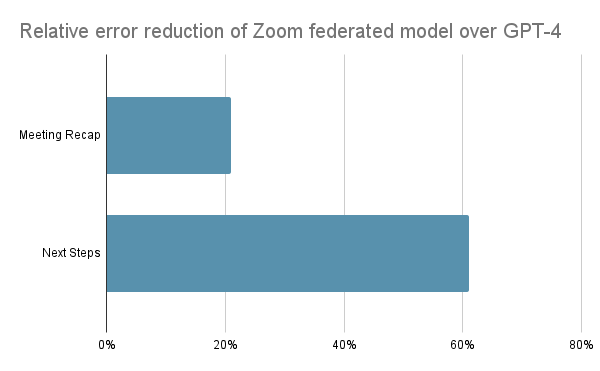
In november 2023 deelde ik hoe de gezamenlijke AI-aanpak van Zoom kwalitatief bijna gelijk stond aan die van OpenAI GPT-4 met slechts 6% van de gevolgtrekkingskosten. Hoe indrukwekkend die resultaten ook waren, inmiddels kunnen we voor onze meest populaire vergaderfuncties nog betere AI-kwaliteit leveren in vergelijking met GPT-4 van OpenAI. Zoom AI Companion verminderde fouten met meer dan 20% (voor de 'uittreksels' van Zooms samenvatting van vergadering) en 60% (voor 'vervolgstappen') in vergelijking met GPT-4 in onze interne, door mensen gevalideerde blinde benchmarking.
Ter ondersteuning van onze trainingsinspanningen om de kwaliteit van voltooide taken te verbeteren, profiteert onze unieke, gezamenlijke aanpak voor AI van vele closed-source en open-source geavanceerde large language models (LLM's), die allemaal samenwerken voor betere resultaten. Dit is in tegenstelling tot andere providers die gebonden zijn aan specifieke LLM's. Zo vertrouwt Microsoft Copilot bijvoorbeeld op GPT-4 en Google op Gemini.
Deze AI-aanpak onderscheidt Zoom AI Companion van de rest en biedt onze klanten een hoogwaardige ervaring met onze populairste functies. Zoals ik in mijn laatste update al aangaf, gebruiken we onze bedrijfseigen Z-scorer om de kwaliteit van onze door AI gegenereerde output te beoordelen. Eerst zetten we een goedkopere LLM in die het meest geschikt is voor de taak. Daarna beoordeelt onze Z-scorer de kwaliteit van de taakvoltooiing. Indien nodig kunnen we nog een extra LLM inzetten om de taak te verfijnen. Dit proces resulteert in een output van hogere kwaliteit. Dit werkt op dezelfde manier als dat mensen in teamverband meer kunnen bereiken dan één individu.
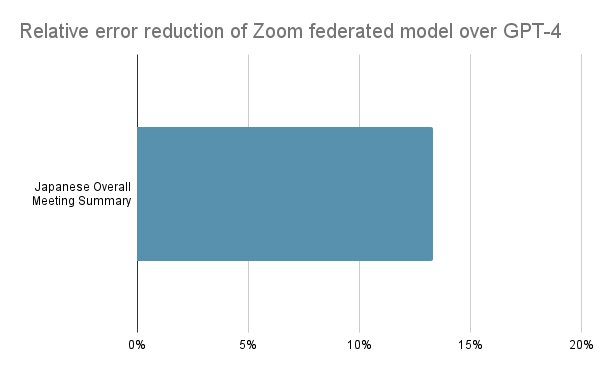
We hebben onze Z-scorer sindsdien verbeterd door aanvullende kwaliteitswaarschuwingen uit verschillende LLM's in te voeren. Bovendien verbeterden we onze gezamenlijke reinforcement learning, om betere aansluiting met menselijke voorkeuren te vinden. Door Zoom LLM samen te voegen met een reeks aanvullende LLM's, is Zooms populaire samenvatting van vergadering van hoge kwaliteit. Zo goed zelfs dat die, volgens onze recente benchmarking, nu beter presteert dan GPT-4, dat wordt gebruikt om Copilot in Microsoft Teams aan te drijven.
Voor wat betreft de veiligheid van AI hebben we bovendien de inherente vooroordelen in de meeste LLM's kunnen terugbrengen. Dit deden we door een comité van meerdere LLM's te vormen, zoals Claude-3, Gemini en GPT-4, zodat we hallucinaties kunnen verminderen en onze Zoom LLM verbeteren. Verschillende LLM's zullen bijvoorbeeld minder snel dezelfde gehallucineerde fout opwekken. Daardoor krijgen we consistentere antwoorden en reduceren we de impact van uitzonderingen.